By Kambiz Shekdar, Ph.D.
Open source drug discovery was proposed in the past in connection with third-world diseases like tuberculosis and malaria, but it is in the context of first-world indications where it is needed most. Despite untold investment by numerous pharmaceutical companies, FDA-approved drugs that target critical brain functions and conditions like anxiety, depression, and sedation continue to present severe and unpredictable side effects, including suicidal ideation. Open source drug discovery will allow more efficient, predicable, and cost-effective development of drugs that work as advertised, with fewer side effects.
In 2001 the Human Genome Project provided the first atlas of all human genes. Twenty years of research, advances in automation, software and AI provide an opportunity for a similar public-private partnership for open source drug research to identify tool compounds corresponding to all proteins.
The omics sciences—including genomics, transcriptomics, and proteomics—have cataloged genes and encoded protein products like Lego building blocks of biology and disease. Variants, including SNPs and mutations, their mRNA expression profiles, alternative splicing of mRNAs, and post-translational modification patterns of proteins have been assembled in public databases. However, a continuing challenge remains as to defining exactly which of these Legos assemble to form the specific multisubunit proteins that mediate biological function and the molecular pathology of disease.
Cell and genetic engineering including RNA interference, zinc-finger nucleases, CRISPR and others continue to tease apart systems biology. Reference or benchmark compounds, selective for specific proteins, are also used to probe biological function in cell-based assays and animal models, including animals where CRISPR is used to disrupt specific genes. But selective compounds for different combinations of heteromultimeric proteins and individual members of large gene families are lacking.
Large panels of robust stable multigene cell lines expressing each combination and member are needed—to discover, characterize and develop such selective compounds. Yet even with CRISPR and other recent cell engineering innovations, the production of just one stable multigene cell line remains a tedious and unpredictable process.
“Almost always, building something is harder than tearing it down,” says Anna Nowogrodzki in The Scientist. Similarly, knocking in genes poses a greater challenge than knocking them out.
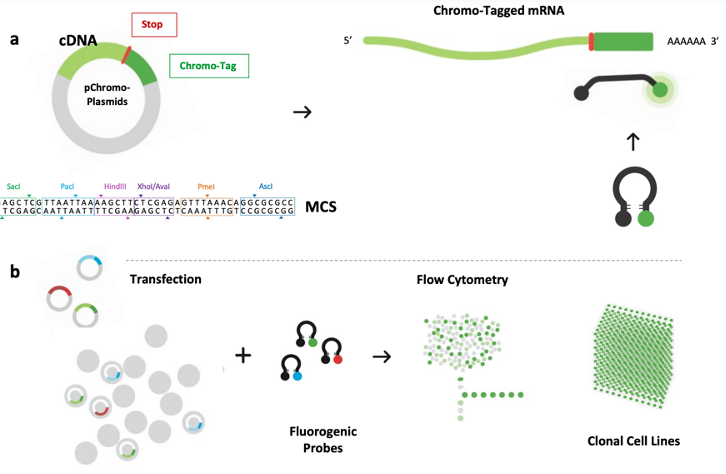
Published earlier this year, Chromovert is a platform cell engineering technology that permits the addition of one or more genes into cells. Example-reported results reveal stable cell lines for notoriously challenging proteins, including those reported to be cytotoxic in mammalian cell cultures such as: epithelial sodium channel (αβγ-ENaC), sodium voltage-gated ion channel 1.7 (NaV1.7-αβ1β2), four unique γ-aminobutyric acid A (GABAA) receptor ion channel subunit combinations α1β3γ2s, α2β3γ2s, α3β3γ2s and α5β3γ2s, cystic fibrosis conductance regulator (CFTR), CFTR-Δ508, and two G protein-coupled receptors (GPCRs).
Like real-time qRT-PCR, the Chromovert method of monitoring gene expression is based on the two broadly applicable principles of nucleic acid hybridization and fluorescence resonance energy transfer (FRET). Unlike PCR methods, however, Chromovert operates in the context of living cells. The technology uses molecular beacons or fluorogenic oligonucleotide signaling probes directed to target genes. Probes are designed to form stem-loop structures, with a fluorophore and quencher paired to absorb emission covalently attached at either terminus, and an intervening target-specific loop sequence. Upon hybridization, probes undergo a fluorogenic conformational change that displaces the fluorophore from the vicinity of the quencher. Positive cells may then be detected and isolated using flow cytometry (see technology flowchart). Optimized research materials to operate Chromovert are available at Secondcell Bio (https://www.secondcellbio.com/).

The total number of human genes has been estimated at 20,000 or more, which can be represented by an equal number of Lego pieces. Which of these Lego building blocks come together? What are all the combinatorial assemblages of subunit combinations of heteromultimeric targets that exist in the body? A public-private partnership using large panels of Chromovert-enabled cell lines could provide the answers.
Research by experts in all fields and two decades of the omics sciences can be used to inform the prioritization of large numbers of proteins for reduction to stable cell lines and cell-based assays. High-throughput screening can be used to discover selective reference compounds. In addition, testing of known drugs and failed drug candidates across the panel can correlate specific subunit combinations with desired clinical efficacy and unwanted side effects, serving to guide the development of safer and more effective drugs.
Finally, the cell lines generated using the open source model can be made available to all research groups for drug discovery. Currently, the industry average failure rate for drug discovery programs in pharmaceutical companies is reported to be approximately 98 percent. Although this includes failures at all stages of the process, the high rate points to a dire need for many improvements in the efficiency and effectiveness of the process. One factor contributing to the high failure rate is the lack of cells that accurately mimic the biology of human disease in the laboratory dish.
As the late Nobel laureate Dr. Gunter Blobel, professor at The Rockefeller University laboratory where Chromovert was invented, said, “You can really test in a much more comprehensive way than you could previously, and, therefore, the technology will probably be important to eliminate side effects or to predict side effects and we can get better, more highly targeted drugs.” For full disclosure, I invented Chromovert Technology while I was a graduate student in Dr. Blobel’s lab.
More information: Shekdar, K., Langer, J., Venkatachalan, S. et al. Cell engineering method using fluorogenic oligonucleotide signaling probes and flow cytometry. Biotechnol Lett 43, 949–958 (2021). doi.org/10.1007/s10529-021-03101-5
Kambiz Shekdar obtained his Ph.D. at The Rockefeller University, where he invented the novel cell engineering method Chromovert Technology and established several research organizations based on it, including Chromocell Corporation, Research Foundation to Cure AIDS (RFTCA) and Secondcell Bio.